Bytes Data Type
Contents
Bytes Data Type#
ToDo:
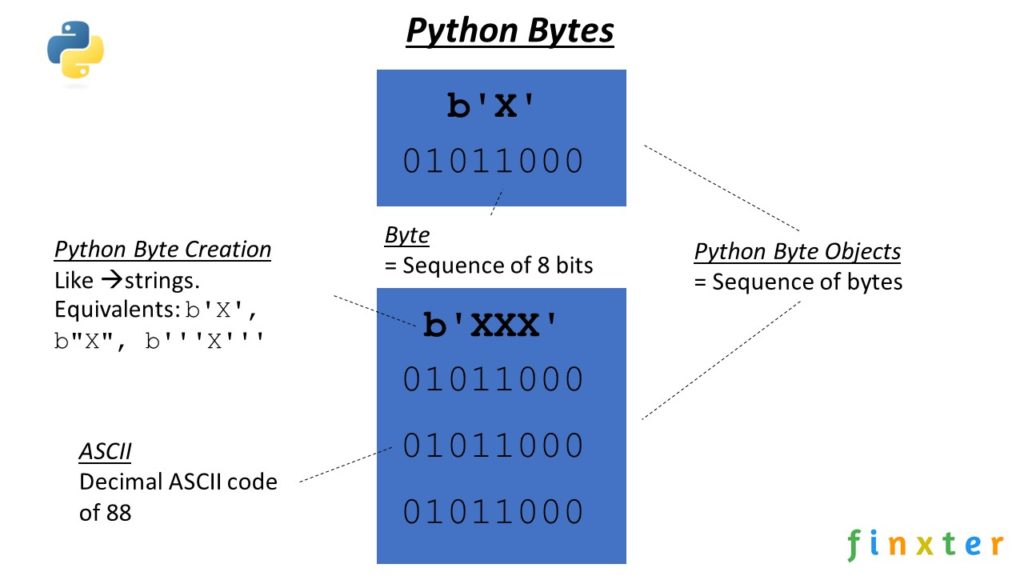
Add an illustration and explain the concept of UTF-8, Unicode, Bytes, ASCII - Similar to this
Add relevant resources at the end
{kind=link}
Most cryptographic functions require Bytes objects. In the case of strings, the encode and decode methods can be used, however for custom objects, two possible ways are:
Converting the object to JSON and then convert the JSON string to bytes
Implementing a
__bytes__method
However, usually hashes are used with plain types like strings which are easily convertible to bytes.
Data Conversions#
data_string = "Hello World!"
data_bytes = data_string.encode("utf-8")
data_hex = data_bytes.hex()
data_decoded = data_bytes.decode("utf-8")
data_hex_bytes = bytes.fromhex(data_hex)
print(f" Original String: {data_string}")
print(f"From String to Bytes: {data_bytes}")
print(f" From Bytes to Hex: {data_hex}")
print(f"From Bytes to String: {data_decoded}")
print(f" From Hex to Bytes: {data_hex_bytes}")
Original String: Hello World!
From String to Bytes: b'Hello World!'
From Bytes to Hex: 48656c6c6f20576f726c6421
From Bytes to String: Hello World!
From Hex to Bytes: b'Hello World!'
Using the binascii module#
The binascii module exposes two utility functions, one to convert from bytes to hex called hexlify and another to do the reverse conversion called unhexlify
Important note: the hexlify function returns a bytes object whereas the .hex() method of bytes returns a string. See the b before the '
import binascii
data_string = "Hello World!"
data_bytes = data_string.encode("utf-8")
data_hex = binascii.hexlify(data_bytes)
data_hex_string = binascii.unhexlify(data_hex)
print(f" Original String: {data_string}")
print(f"From String to Bytes: {data_bytes}")
print(f" From Bytes to Hex: {data_hex}")
print(f" From Hex to Bytes: {data_hex_bytes}")
Original String: Hello World!
From String to Bytes: b'Hello World!'
From Bytes to Hex: b'48656c6c6f20576f726c6421'
From Hex to Bytes: b'Hello World!'
Examples#
import hashlib
Example with plain strings#
data = "Hello World!"
data_bytes = data.encode("utf-8")
data_decoded = data_bytes.decode("utf-8")
data_hashed = hashlib.sha256(data_bytes).hexdigest()
print(f"Original: {data}")
print(f" Encoded: {data_bytes}")
print(f" Decoded: {data_decoded}")
print(f" Hashed: {data_hashed}")
Original: Hello World!
Encoded: b'Hello World!'
Decoded: Hello World!
Hashed: 7f83b1657ff1fc53b92dc18148a1d65dfc2d4b1fa3d677284addd200126d9069
Example with Custom objects#
from dataclasses import dataclass, asdict
import json
@dataclass
class Person:
first_name: str
last_name: str
@property
def fullname(self):
return f"{self.last_name}, {self.first_name}"
def __bytes__(self):
dictionary_representation = asdict(self)
json_representation = json.dumps(dictionary_representation)
return json_representation.encode("utf-8")
@classmethod
def from_bytes(cls, bytes_object):
string_representation = bytes_object.decode("utf-8")
dictionary_representation = json.loads(string_representation)
return cls(**dictionary_representation)
person = Person("John", "Doe")
person_bytes = bytes(person)
person_decoded = Person.from_bytes(person_bytes)
person_hashed = hashlib.sha256(person_bytes).hexdigest()
print(f" Original: {person}")
print(f" Encoded: {person_bytes}")
print(f" Decoded: {person_decoded}")
print(f"Full Name: {person_decoded.fullname}")
print(f" Hashed: {person_hashed}")
Original: Person(first_name='John', last_name='Doe')
Encoded: b'{"first_name": "John", "last_name": "Doe"}'
Decoded: Person(first_name='John', last_name='Doe')
Full Name: Doe, John
Hashed: fee485b19074e0b0b2856ae5f27fcdd67ff12204cbff73c5eaa10b1aac887042
Example with Mixins#
In bigger projects, it may be against best practice to duplicate the __bytes__ and from_bytes methods. A Mixin class can be used and then inherit from. Mixins are special class, similar to a Protocol which define methods to be used in child classes. Mixins as opposed to Interfaces or Abstract Classes are meant to be incomplete and it should not make sense to instanciate them directly.
Note: In this case, it would have been possible to make PersonBase inherit from ByteConvertibleMixin and thus avoiding the multiple-inheritance. However, if the bytes conversion is desirable only to a subset of children classes of PersonBase, then the multiple-inheritance approach is the most idiomatic in Python.
from abc import ABC
from dataclasses import dataclass, asdict
import json
@dataclass
class ByteConvertibleMixin(ABC):
def __bytes__(self):
dictionary_representation = asdict(self)
json_representation = json.dumps(dictionary_representation)
return json_representation.encode("utf-8")
@classmethod
def from_bytes(cls, bytes_object):
string_representation = bytes_object.decode("utf-8")
dictionary_representation = json.loads(string_representation)
return cls(**dictionary_representation)
@dataclass
class PersonBase: # Name changed to avoid overwriting
first_name: str
last_name: str
@property
def fullname(self):
return f"{self.last_name}, {self.first_name}"
@dataclass
class Customer(PersonBase, ByteConvertibleMixin): # Multiple-Inheritance
address: str
customer = Customer("John", "Doe", "Neverland 10")
customer_bytes = bytes(customer)
customer_decoded = Customer.from_bytes(customer_bytes)
customer_hashed = hashlib.sha256(customer_bytes).hexdigest()
print(f" Original: {customer}")
print(f" Encoded: {customer_bytes}")
print(f" Decoded: {customer_decoded}")
print(f"Full Name: {customer_decoded.fullname}")
print(f" Hashed: {customer_hashed}")
Original: Customer(first_name='John', last_name='Doe', address='Neverland 10')
Encoded: b'{"first_name": "John", "last_name": "Doe", "address": "Neverland 10"}'
Decoded: Customer(first_name='John', last_name='Doe', address='Neverland 10')
Full Name: Doe, John
Hashed: 4a23851a4c1d84ccd1b5b9c520325436c162b823a998feceeb87f7fb107876bc
Special Case: Files#
When working with files, it is possible to work in bytes format out of the box. The easiest way is through the read_bytes method of the pathlib module.
from pathlib import Path
image_bytes = Path("../_static/images/certificate_details_dns.png").read_bytes()
image_bytes = image_bytes[:150] # Trimmed to improve display
print(f"Byte Representation: \n{image_bytes}\n")
print(f"Hex Representation: \n{image_bytes.hex()}")
Byte Representation:
b'\x89PNG\r\n\x1a\n\x00\x00\x00\rIHDR\x00\x00\x04\xe1\x00\x00\x02\x0f\x08\x02\x00\x00\x00\xba\xd9]t\x00\x00\x00\x01sRGB\x00\xae\xce\x1c\xe9\x00\x00\x00\x04gAMA\x00\x00\xb1\x8f\x0b\xfca\x05\x00\x00\x00\tpHYs\x00\x00\x0e\xc3\x00\x00\x0e\xc3\x01\xc7o\xa8d\x00\x00\xb9}IDATx^\xed\xfd\x7f\xace\xc7u\xe7\x8b\xf5\xfb#x\xf93\xc8\x1f\x1e\xc0\x7f\xbdI\x10\xc0\x80\x9d\xf1\x1f\xf2C@\xe5\xe5\x0f\x033H\x9cA\x0c? \x99\x18\xcc@Q@\xe5\x8e\x07\x03\xd9\x83\x17@\x8e'
Hex Representation:
89504e470d0a1a0a0000000d49484452000004e10000020f0802000000bad95d74000000017352474200aece1ce90000000467414d410000b18f0bfc6105000000097048597300000ec300000ec301c76fa8640000b97d49444154785eedfd7fac65c775e78bf5fb2378f933c81f1ec07fbd4910c0809df11ff24340e5e50f0333489c410c3f209918cc405140e58e0703d98317408e
Random Bytes#
There are many ways to generate randomness or pseudo-randomness, some of which are considered insecured and other secure.
Using the secrets module#
Python 3.6 introduced the secrets module to conveniently generate several types of secure random bytes.
The relevant methods are the token_* methods, each receives a lenght parameter. The more bytes, the safer the token, see this resource for more information. Moreover, this video illustrates how secure 32 bytes (256bits) randomness is.
When using only hexadecimal, there will be 2 characters per byte, to generate shorter strings but at the same time being able to insert them in URL (e.g. for password reset tokens), the token_urlsafe can be used, which will yield a string approximately 25% shorter
There are other ways to generate random bytes in Python but using secrets is common practice since Python 3.6. For other options see this detailed answer.
import secrets
lenght = 15
print(f" Secure Random Bytes: {secrets.token_bytes(lenght)}")
print(f" Secure Random Bytes (Hex): {secrets.token_hex(lenght)}")
print(f"Secure Random Bytes (Hex URLSafe): {secrets.token_urlsafe(lenght)}")
Secure Random Bytes: b';\x0f\xb4\xdb\xf6*O\xc6a|o\x92\xc3\x82{'
Secure Random Bytes (Hex): 99bf49794fa7411a0f472a459a8df2
Secure Random Bytes (Hex URLSafe): Vx25EMsEuVszsq995uQf
Comparing Secrets#
To avoid timming attacks, it is important to NOT use == when comparing secrets. For that the secrets module exposes a method compare_digest which is actually an alias of the hmac module homonymous method.
For a demonstration of this type of attack, see this demo.
# Excesively large lenght for better illustration
lenght = 1000
real_token = secrets.token_bytes(lenght)
guess_token_all_wrong = secrets.token_bytes(lenght)
guess_token_all_but_one = real_token[:-1] + secrets.token_bytes(1)
print(f"Is short guess the real? {secrets.compare_digest(real_token, guess_token_all_wrong)}")
print(f"Is long guess the real? {secrets.compare_digest(real_token, guess_token_all_but_one)}")
print(f"Is real guess the real? {secrets.compare_digest(real_token, real_token)}")
Is short guess the real? False
Is long guess the real? False
Is real guess the real? True
Conclusion#
To avoid duplicated work, it is important to work with standards, in the case of security and encryption, that standard is the Bytes format. All methods and algorithms work with bytes objects and therefore it is important to know how to handle them while programming.
Python has several tools like bytes, binascii and secrets to work, generate and convert bytes. It is also possible to define conversion for custom objects through the __bytes__ magic method. The pathlib module also allows to read files as bytes out of the box.